



群晖Nas中Docker搭建社工库
1、介绍
社工库是黑客与大数据方式进行结合的一种产物,黑客们将泄漏的用户数据整合分析,然后集中归档的一个地方。这些用户数据大部分来自社工库论坛上,黑客们脱库撞库获得的数据包,包含的数据类型除了账号密码外,还包含被攻击网站所属不同行业所带来的附加数据。社工库的搭建不是简单地将数据导入mysql数据库,然后通过php做个select * from sgk where username like'%xxxxx%'这样就能完事的,上面这样的查询方式,真要用于社工库查询,几个亿的数据查一条记录恐怕得半小时才能搜索出想要的结果。好在这个问题早就被一种叫做全文搜索引擎的东西解决了。目前主流的全文搜索引擎有Lucene、Solr、Elastic search等,后两者的基础都是Lucene,基于java。全文搜索引擎也经常被用于大数据。Solr通过jdbc接口可以导入各种数据库和各种格式的数据,非常适合开发企业级的海量数据搜索平台,并且提供完善的solr cloud集群功能,更重要的是,solr的数据查询完全基于http,可以通过简单的post参数,返回json,xml,php,python,ruby,csv等多种格式。
2、配置
软件配置:Solr 8.11.1 + Mysql 8.0.29
硬件配置:群晖NAS DS920+
3 、环境安装
3.1、Docker程序的安装
选择套件中心中的Docker程序,选择一键安装

3.2、Mysql数据库的安装
1、首先点击左边的注册表
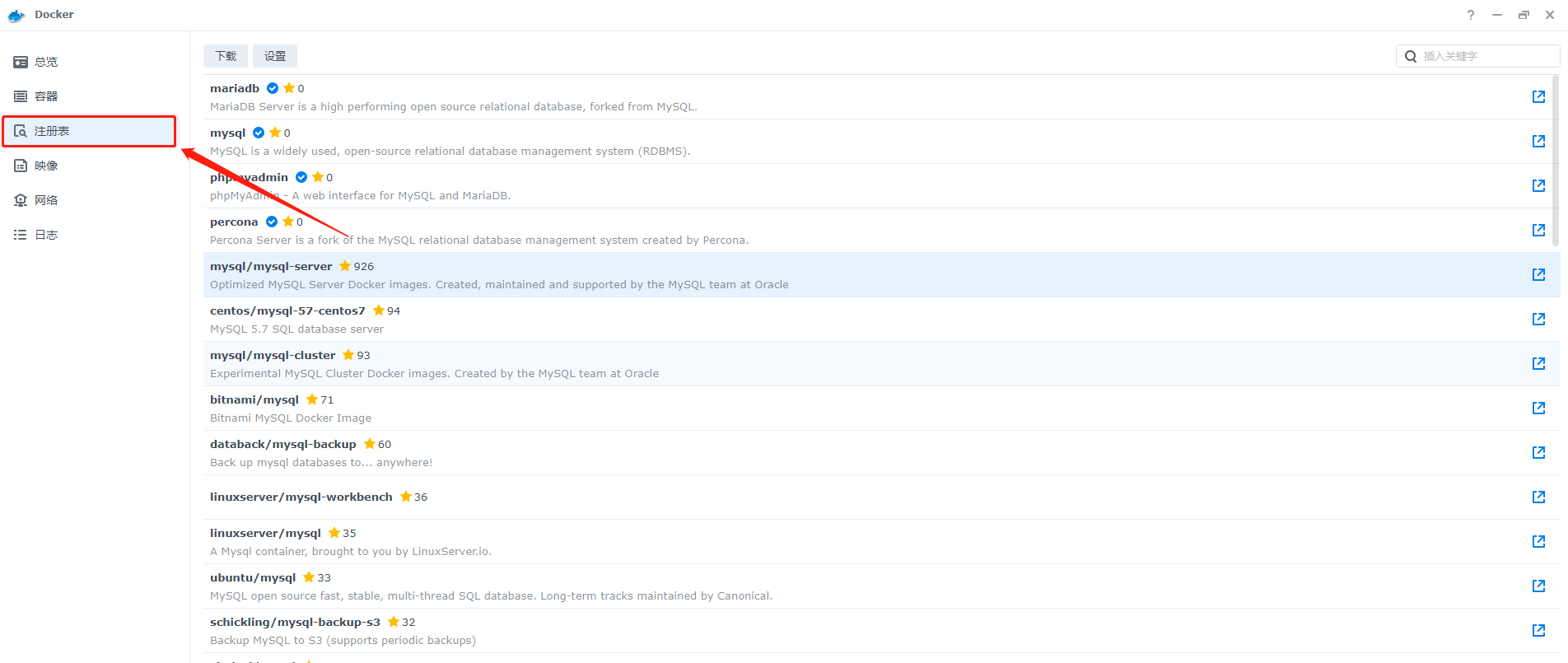
2、右上角搜索栏搜索mysql
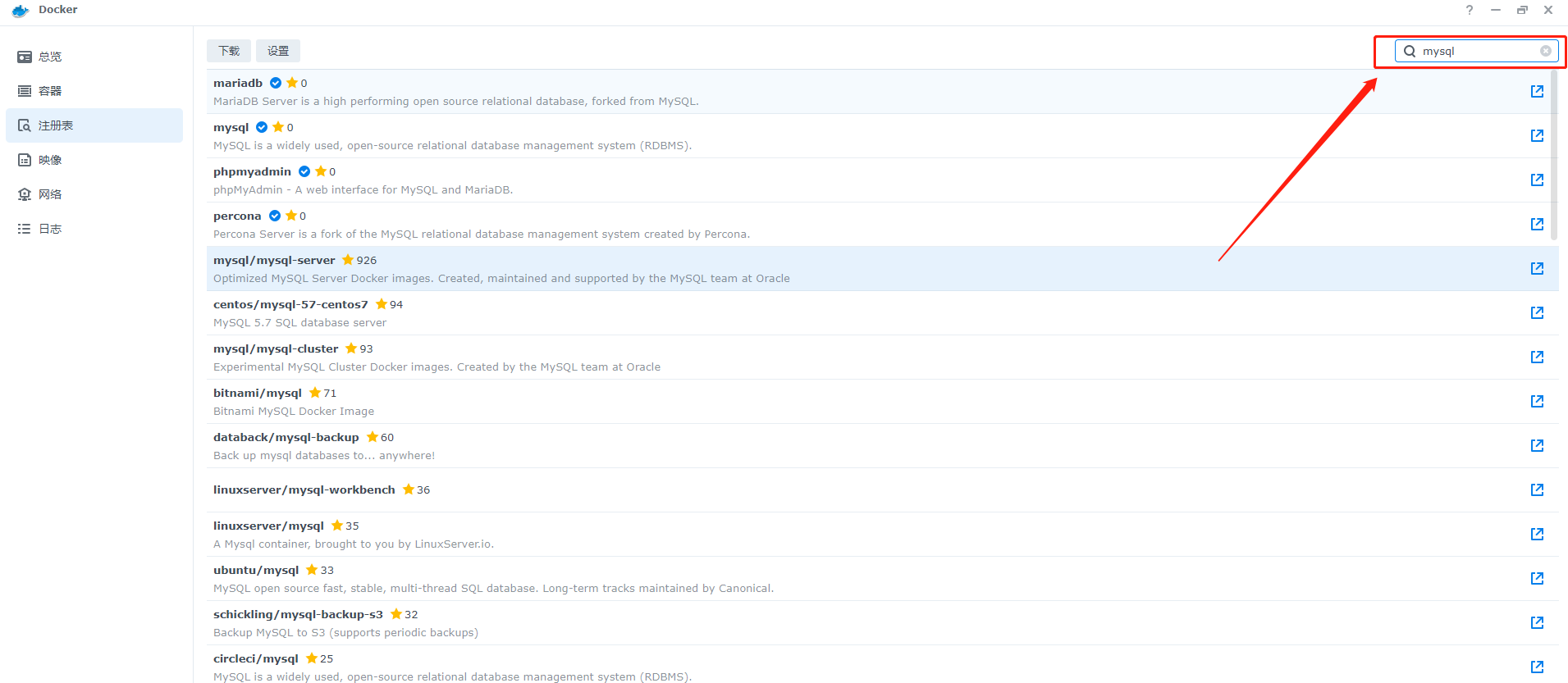
3、在对应的docker项目上右键,选择下载映像
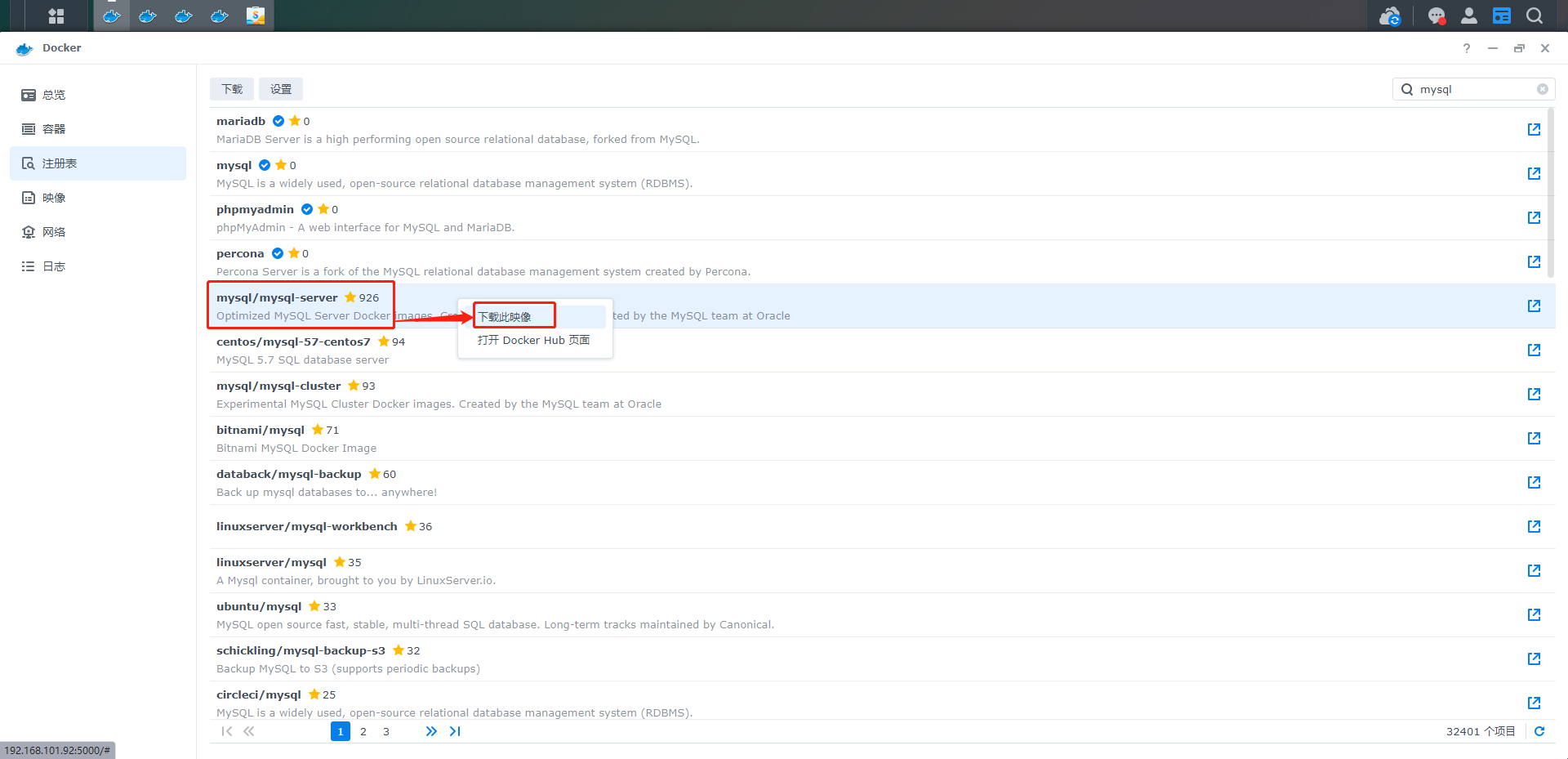
4、点击后会出现版本选择,我们选择last,也就时最新版本
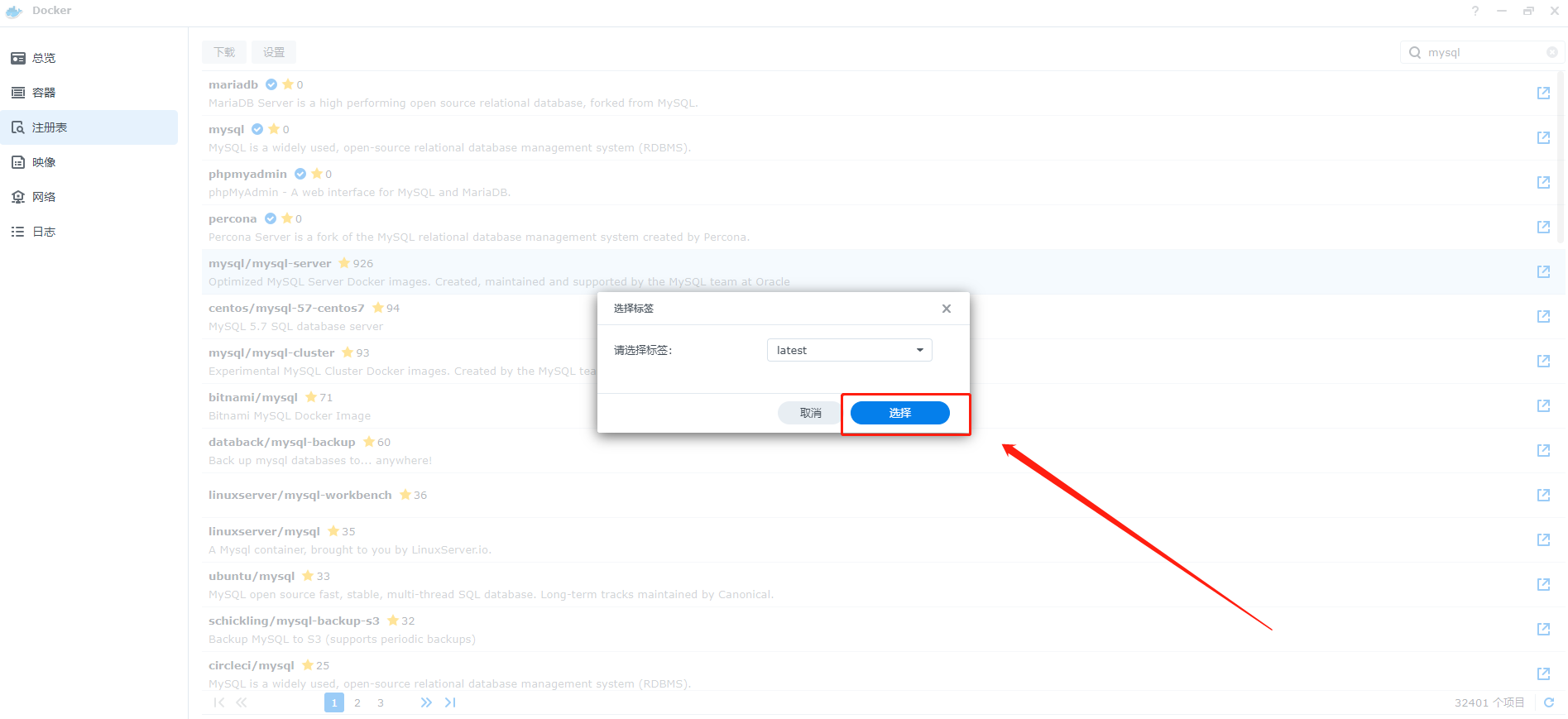
5、下载完成的镜像会出现在映像中
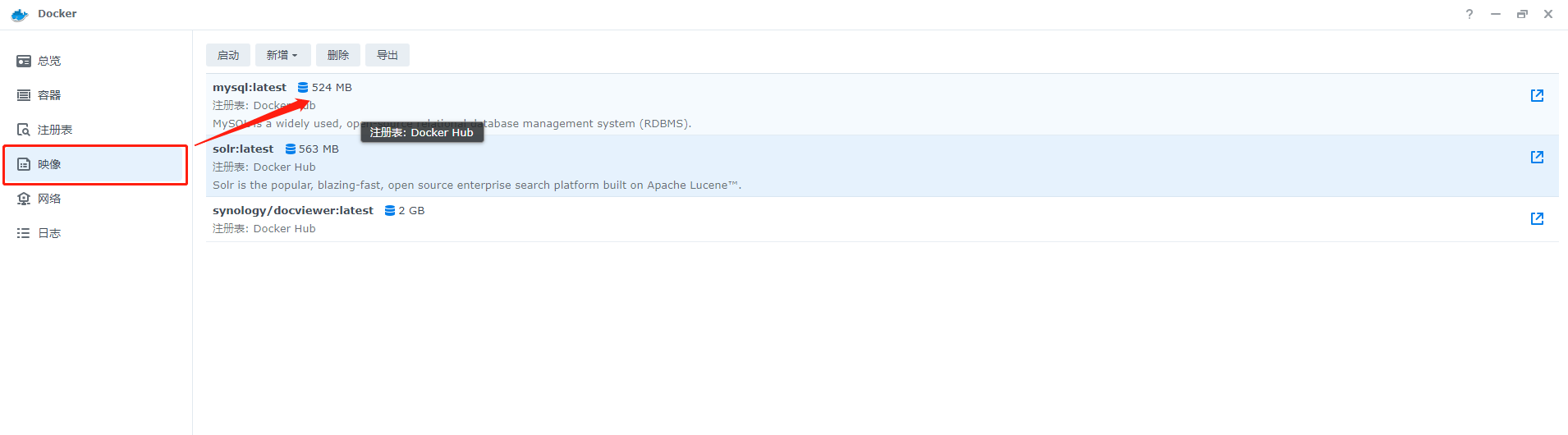
6、选择mysql项后,直接点击启动会出现docker的配置信息,直接选择下一步
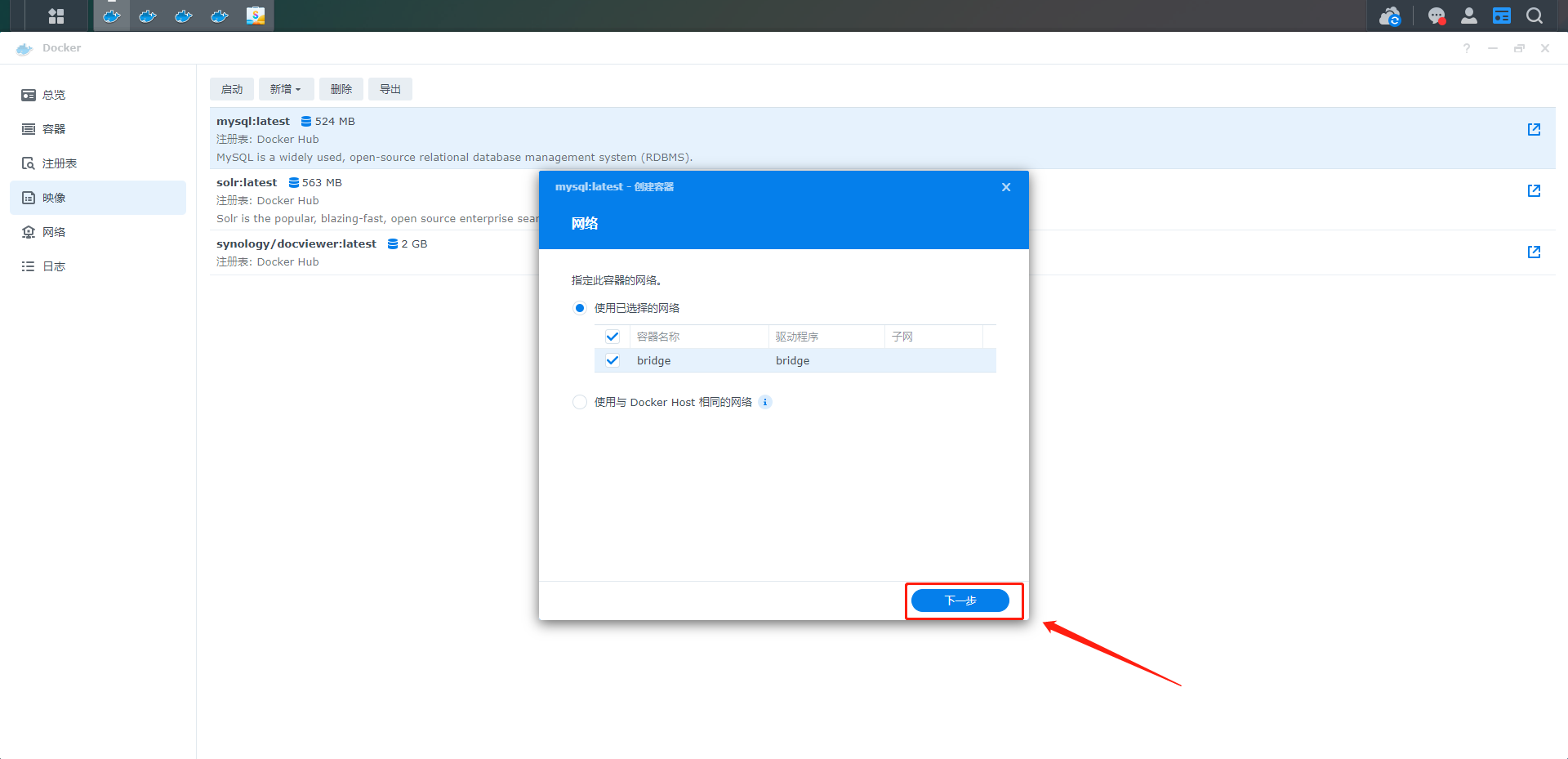
7、常规设置和端口设置可以选择默认
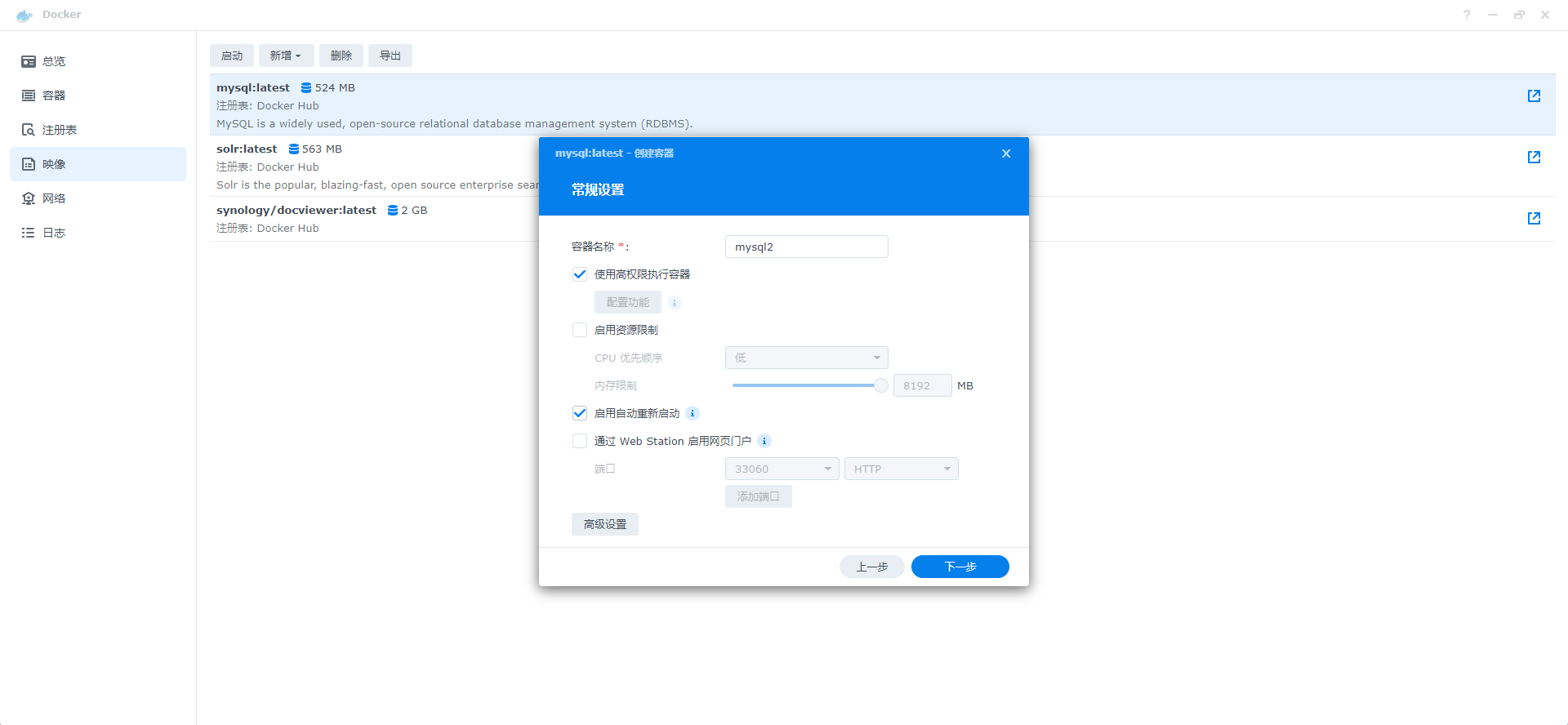
8、点击高级设置,增加MYSQL_ROOT_PASSWORD字段,设置数据库的初始密码,保存后点击下一步
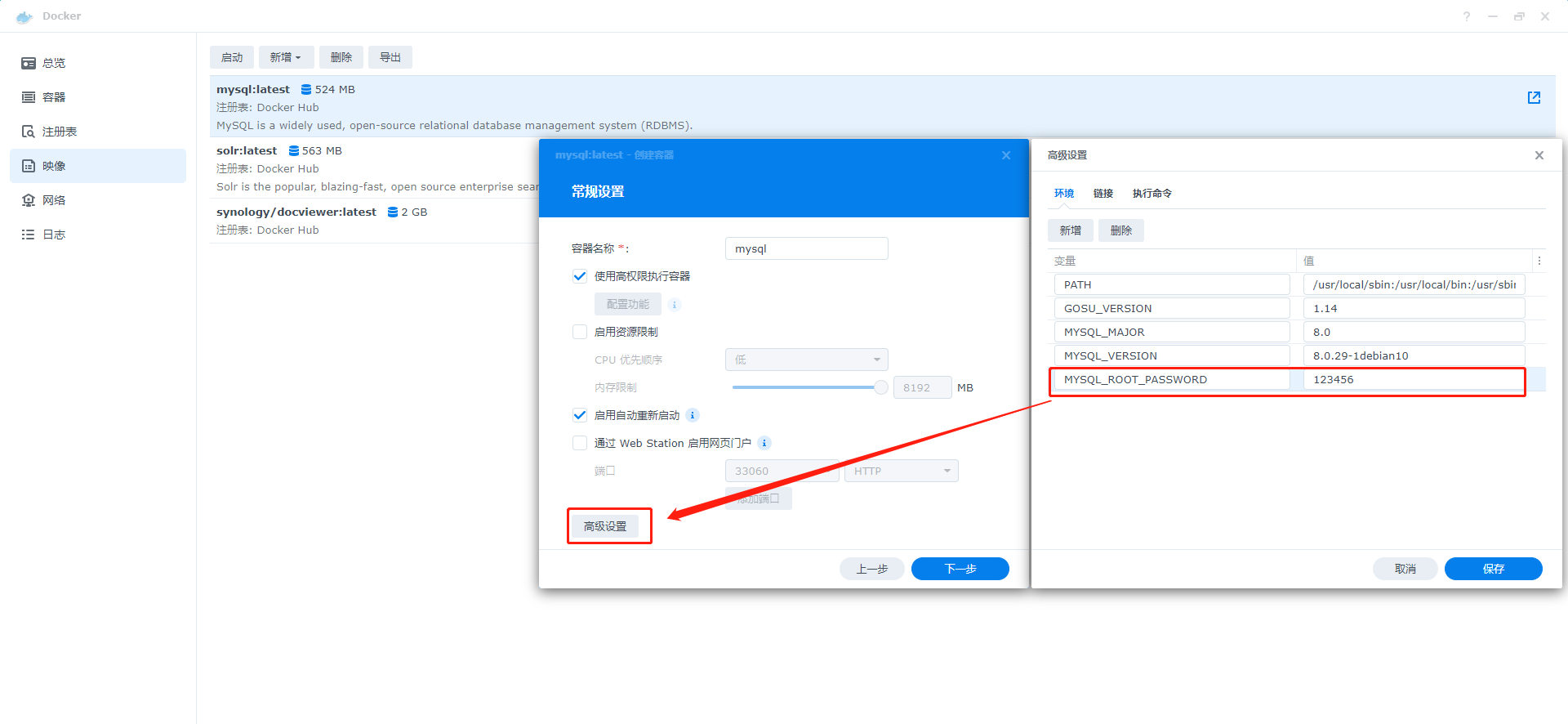
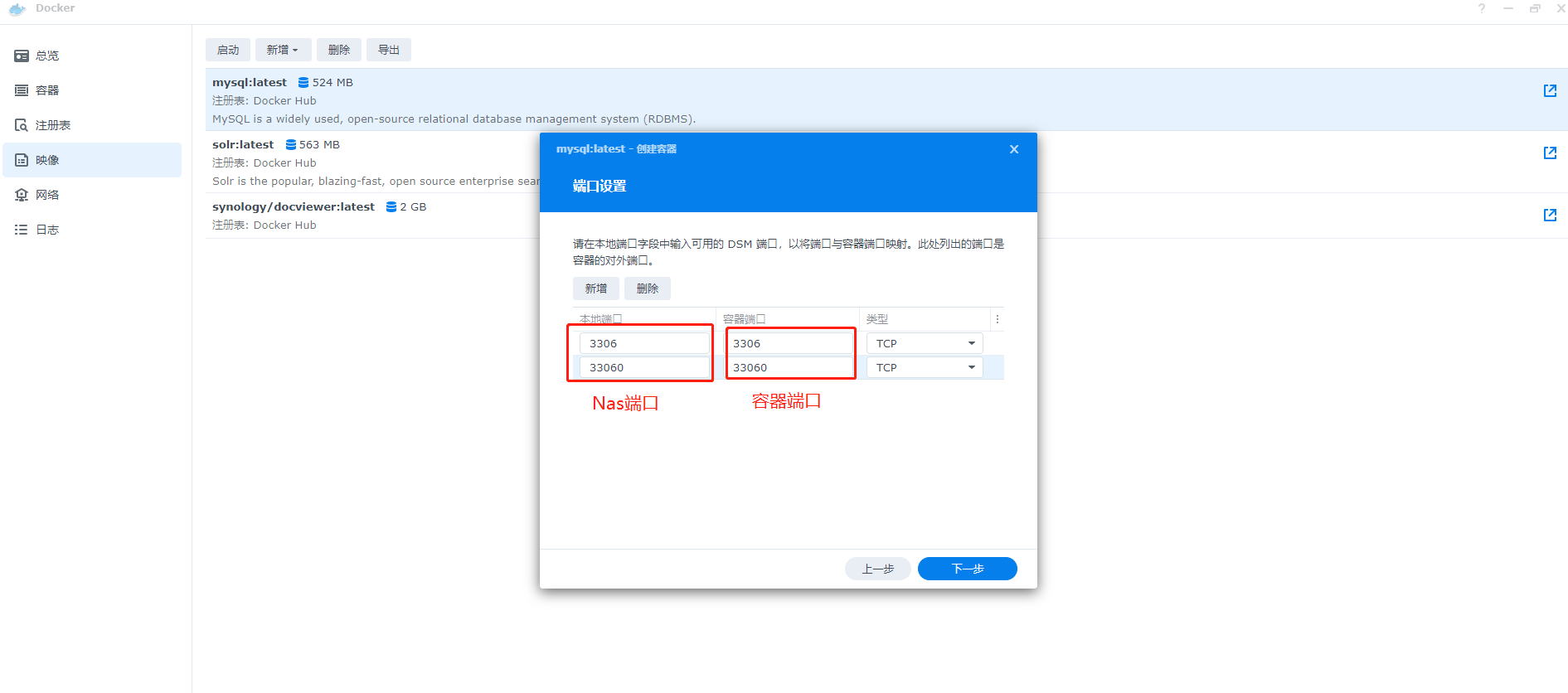
9、设置Nas端口和容器端口,下一步
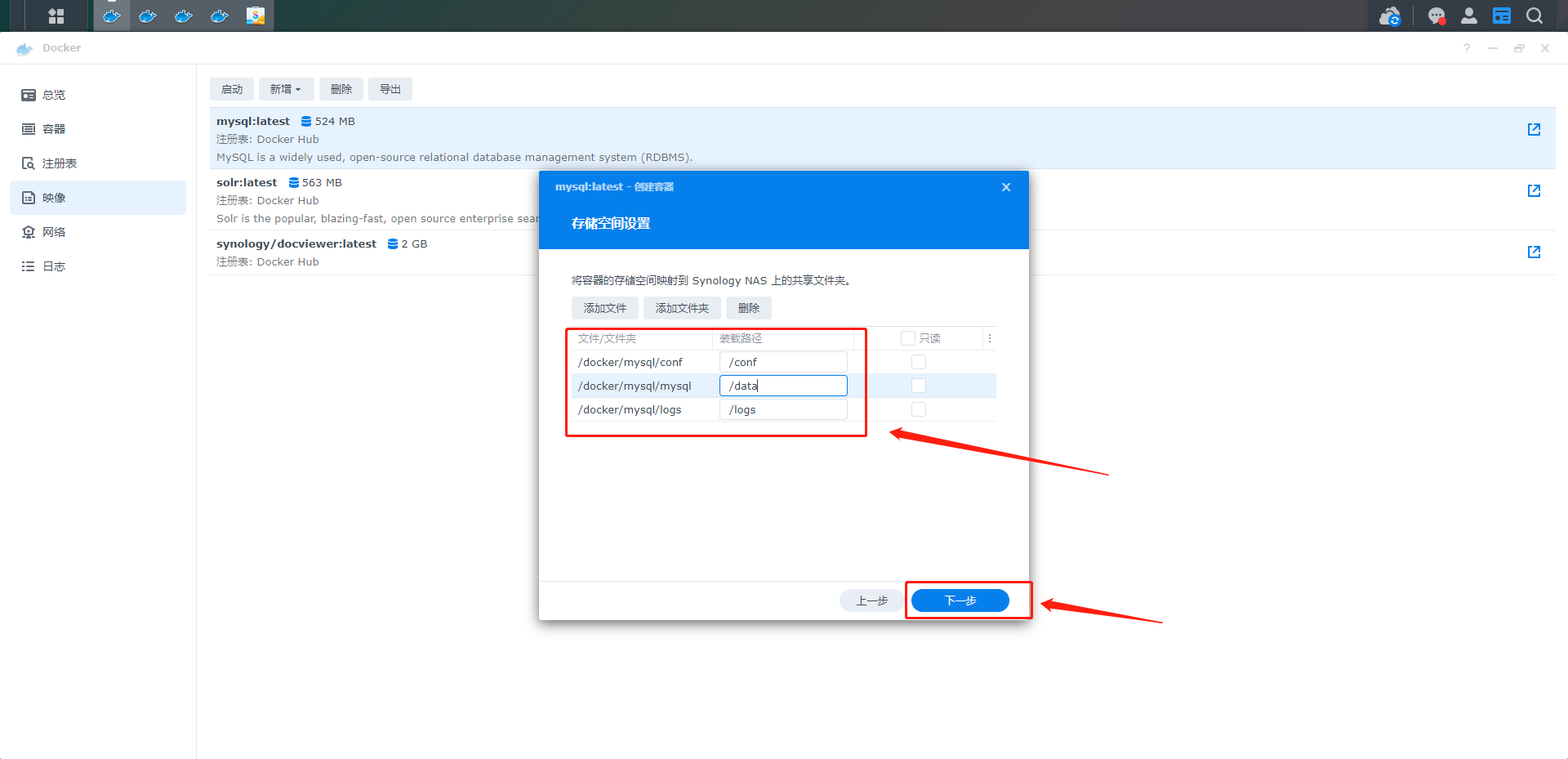
10、设置的文件夹是Docker与Nas共享的文件夹,可用于传输、共享文件
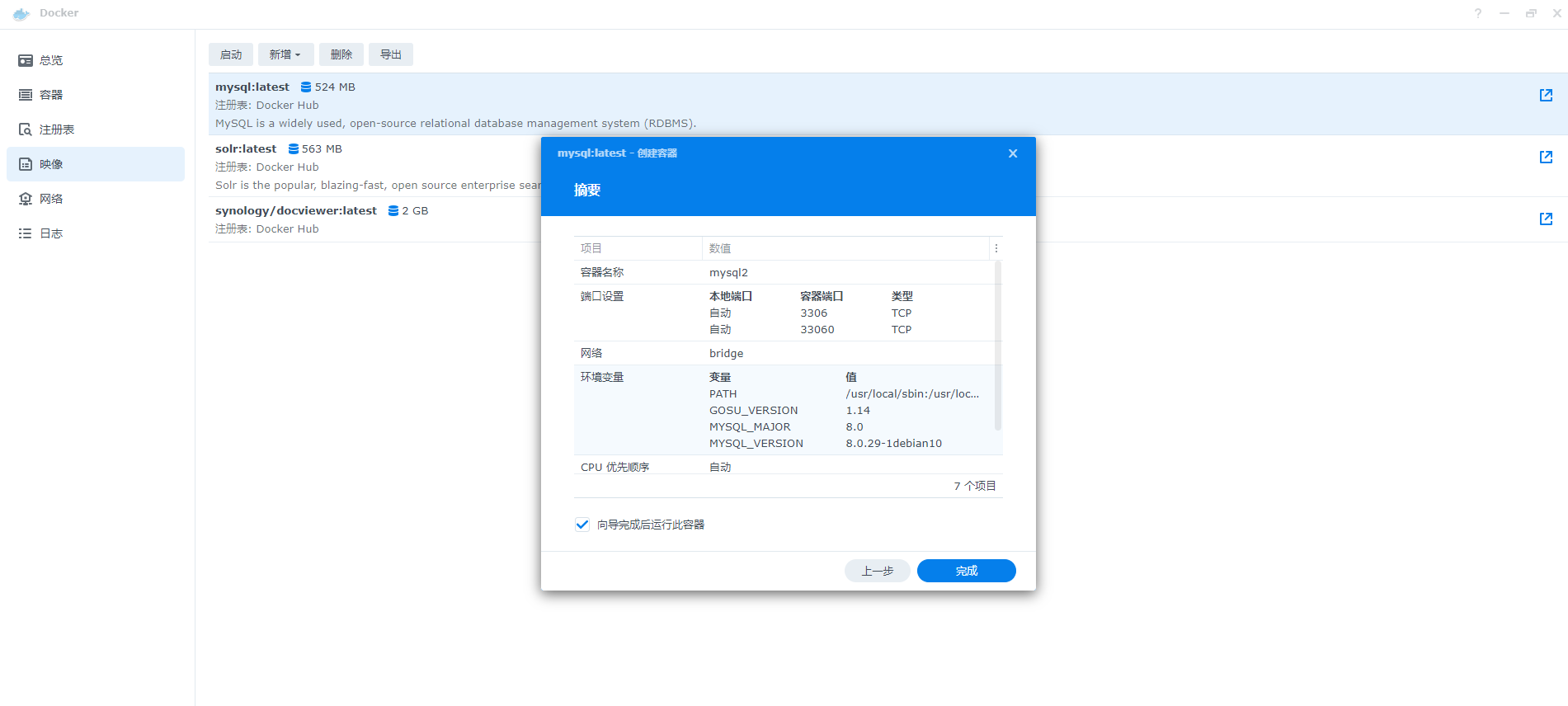
11、最后完成后,可以在容器中看到mysql的Docker处于运行状态
12、在终端界面新建一个终端,输入mysql -u root -p 回车,输入创建容器时设的密码,进入mysql>
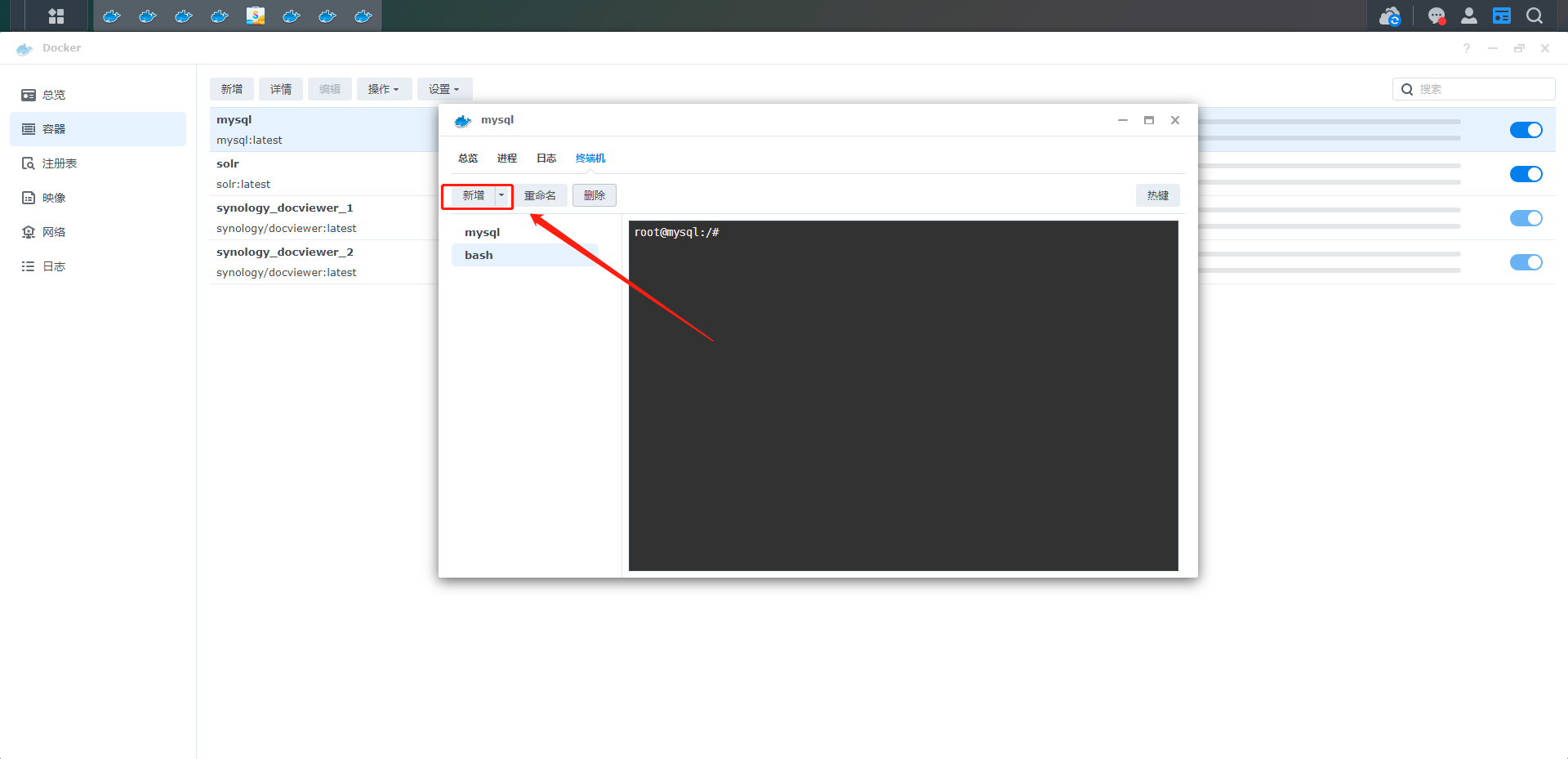
13、在终端中输入sql,修改root用户的远程连接权限
grant all privileges on *.* to 'root'@'%';
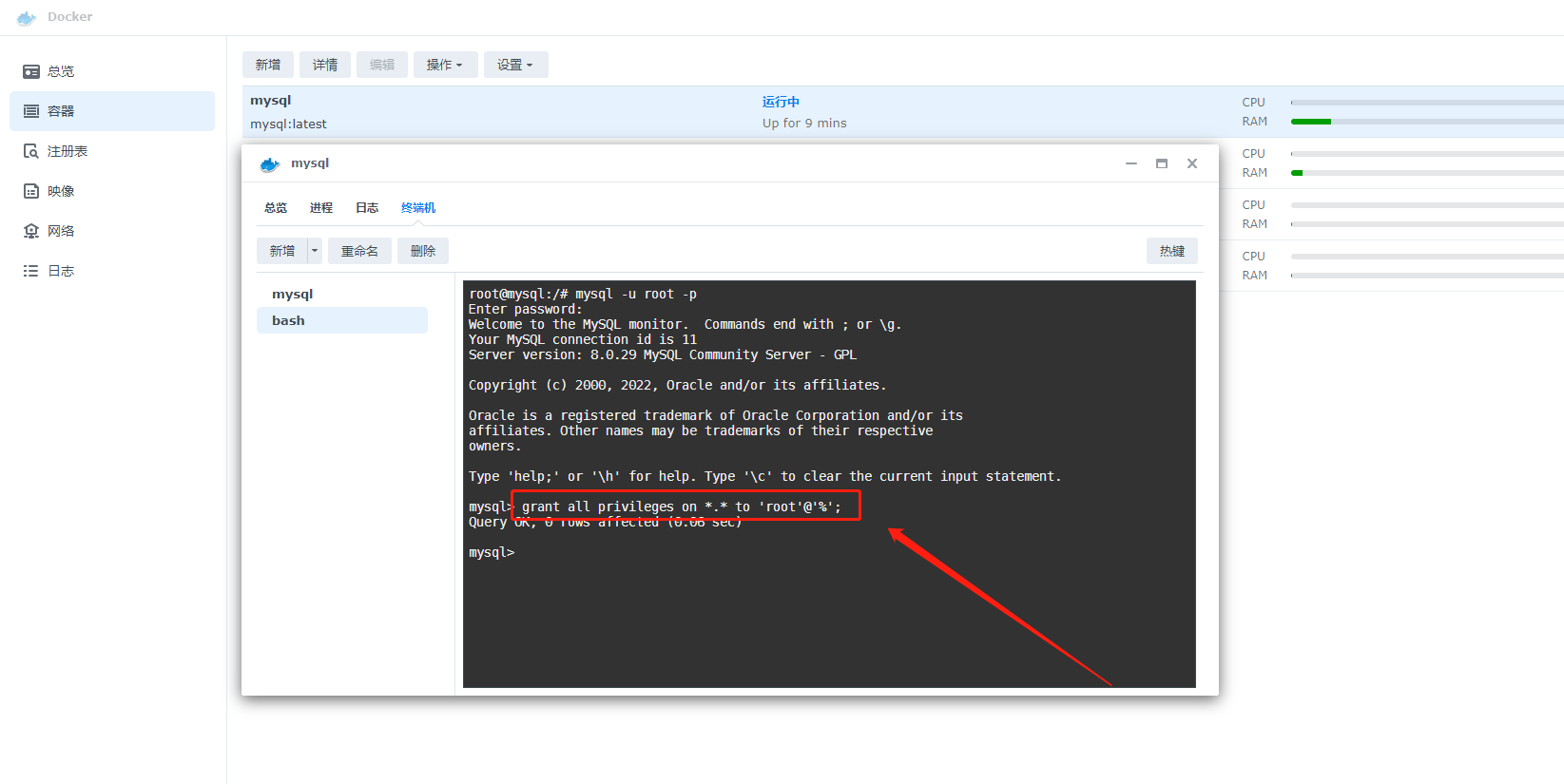
14、终端中输入sql,可以看到root用户的连接没有限制
select Host,User,plugin from mysql.user;
15、使用Navicat尝试连接数据库,能够成功连接
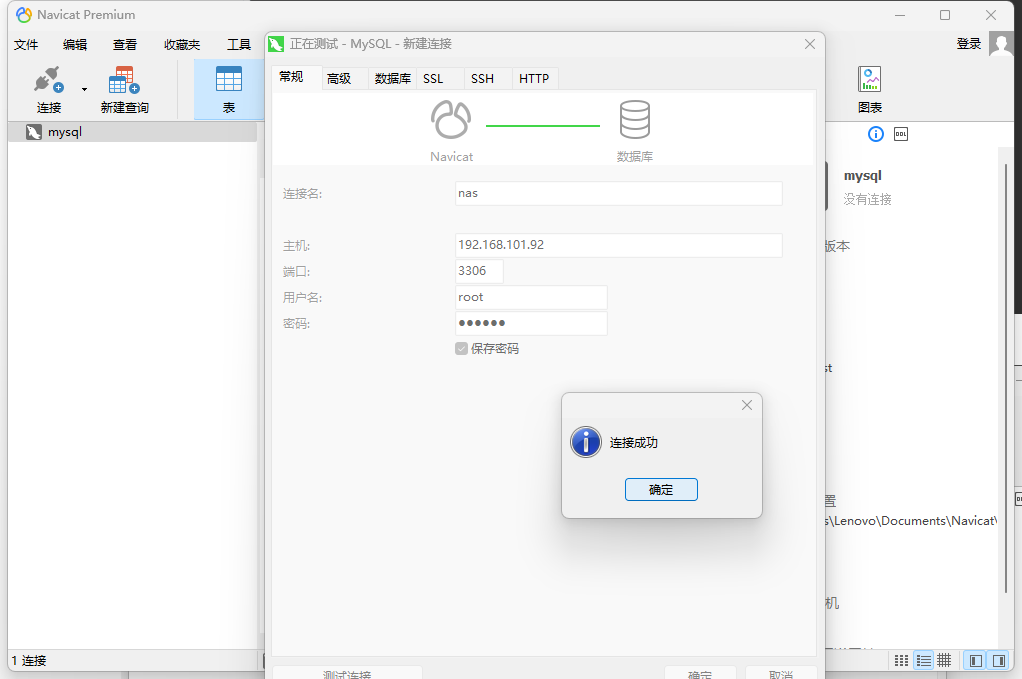
3.3、数据库字段设计
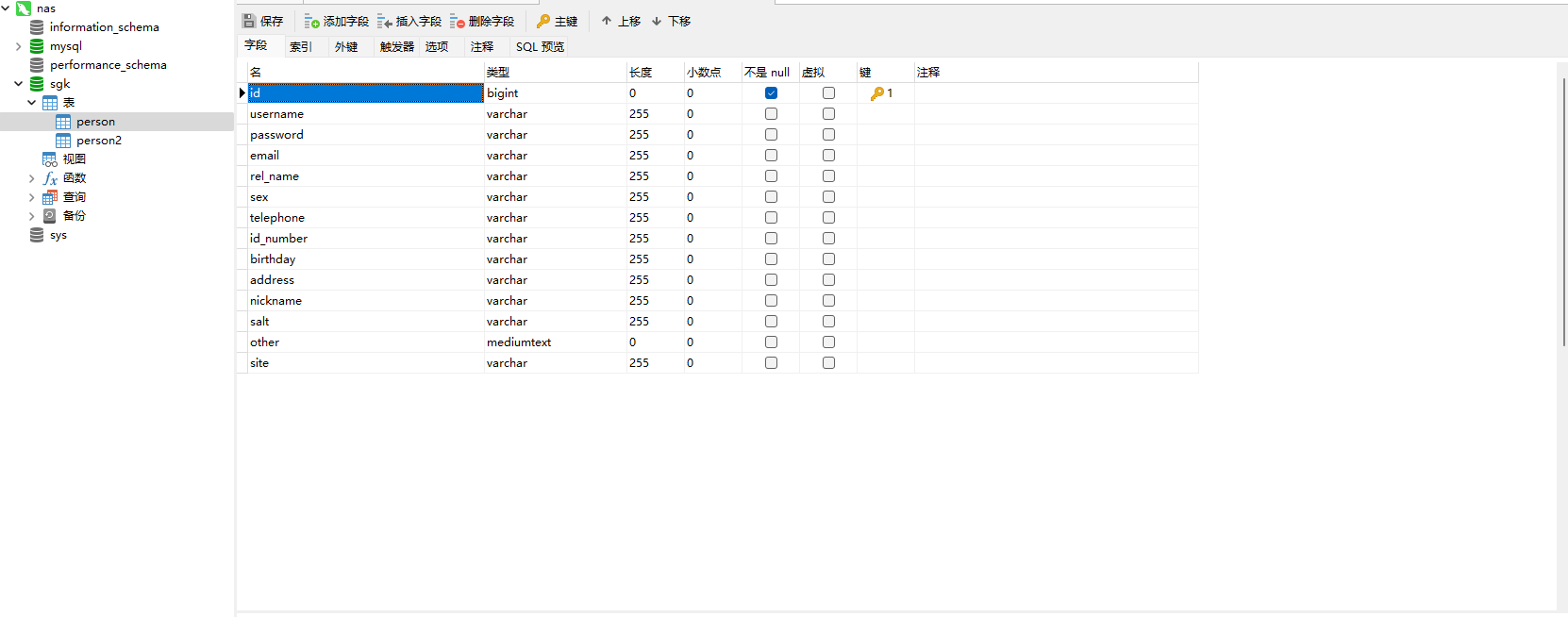
3.4、Solr搜索引擎的安装
1、映像的下载方式与数据库的相同,也是选择最新的版本
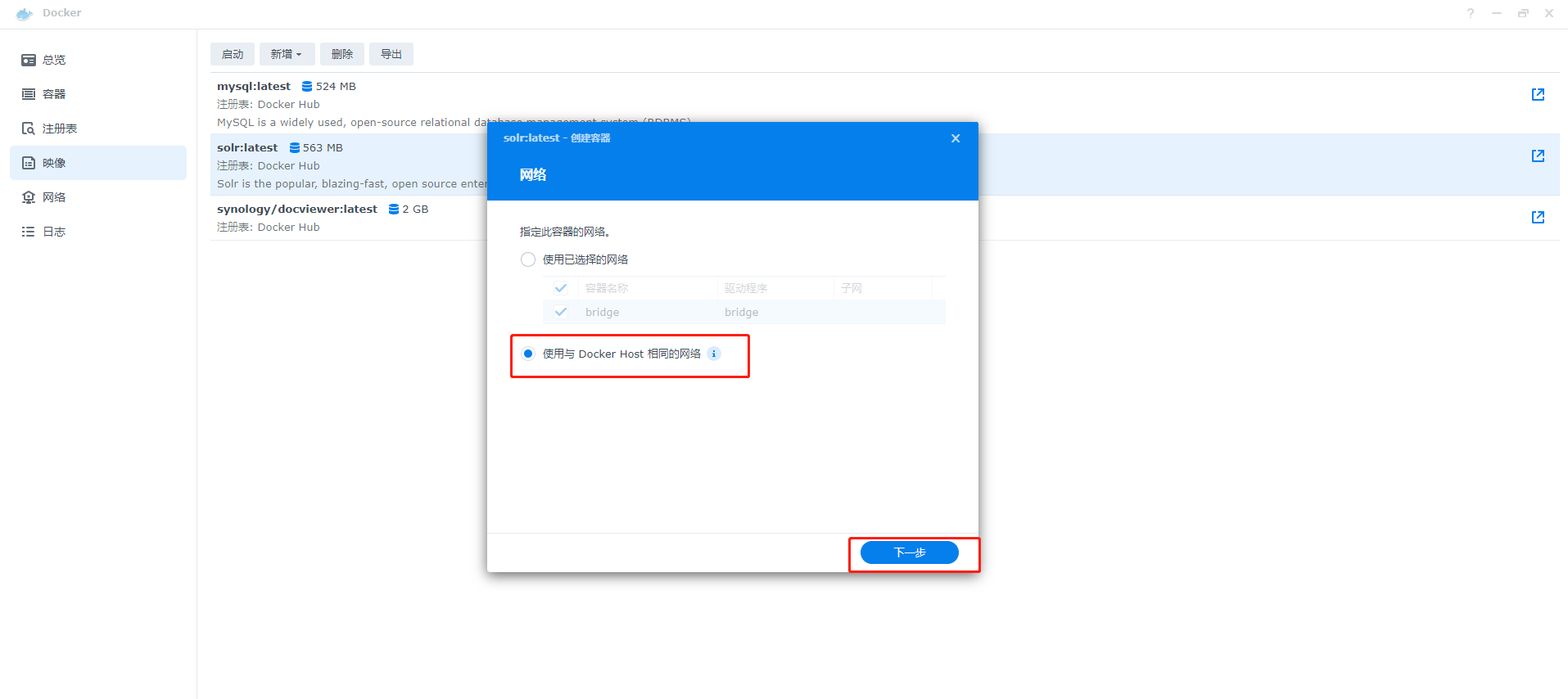
2、配置网络,选择第二个选择,然后下一步
3、需要基于较高的执行权限,方便后面的配置文件修改
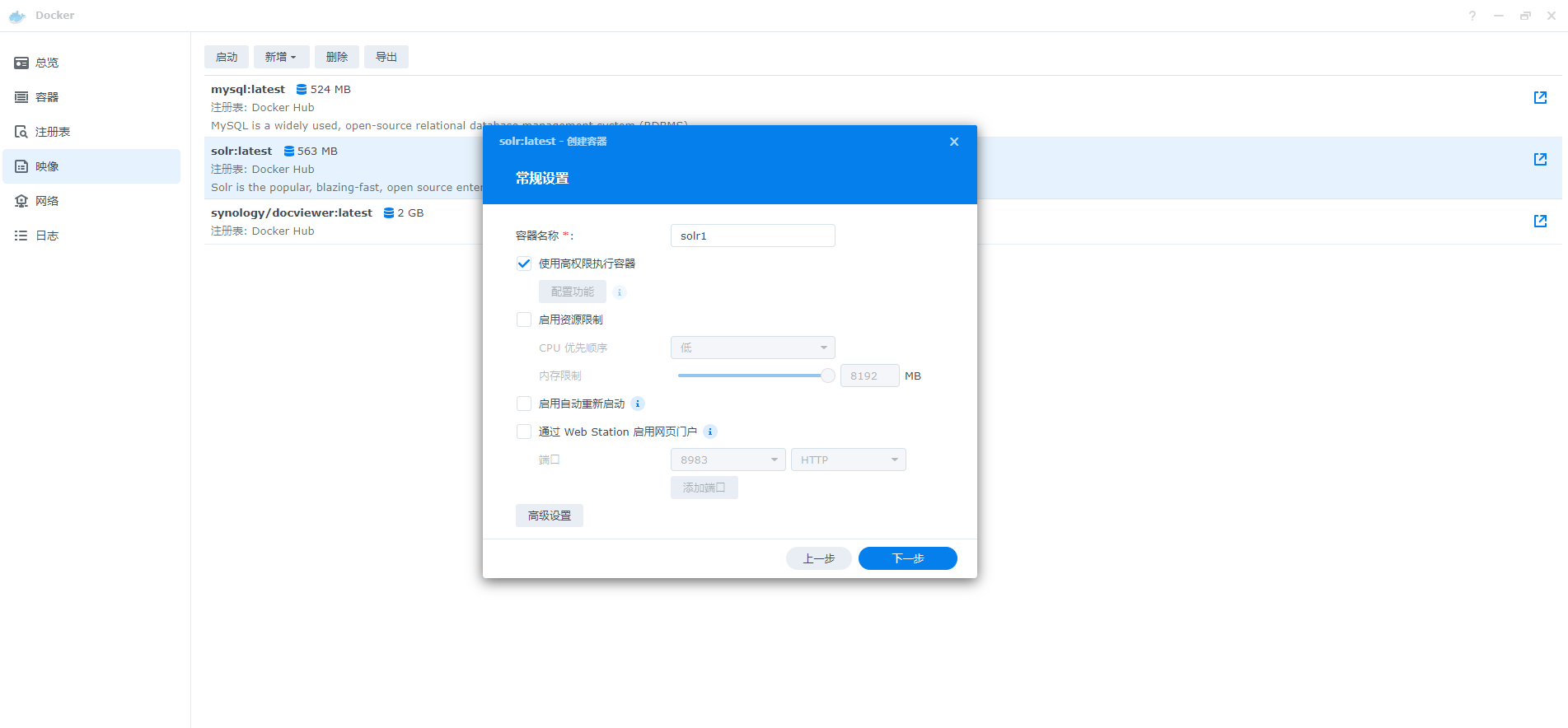
4、同样需设置共享文件夹,方便配置文件的修改,因为Docker中用于修改配置文件的文本编辑器安装由于网络问题会导致安装不上,下一步后就可完成安装
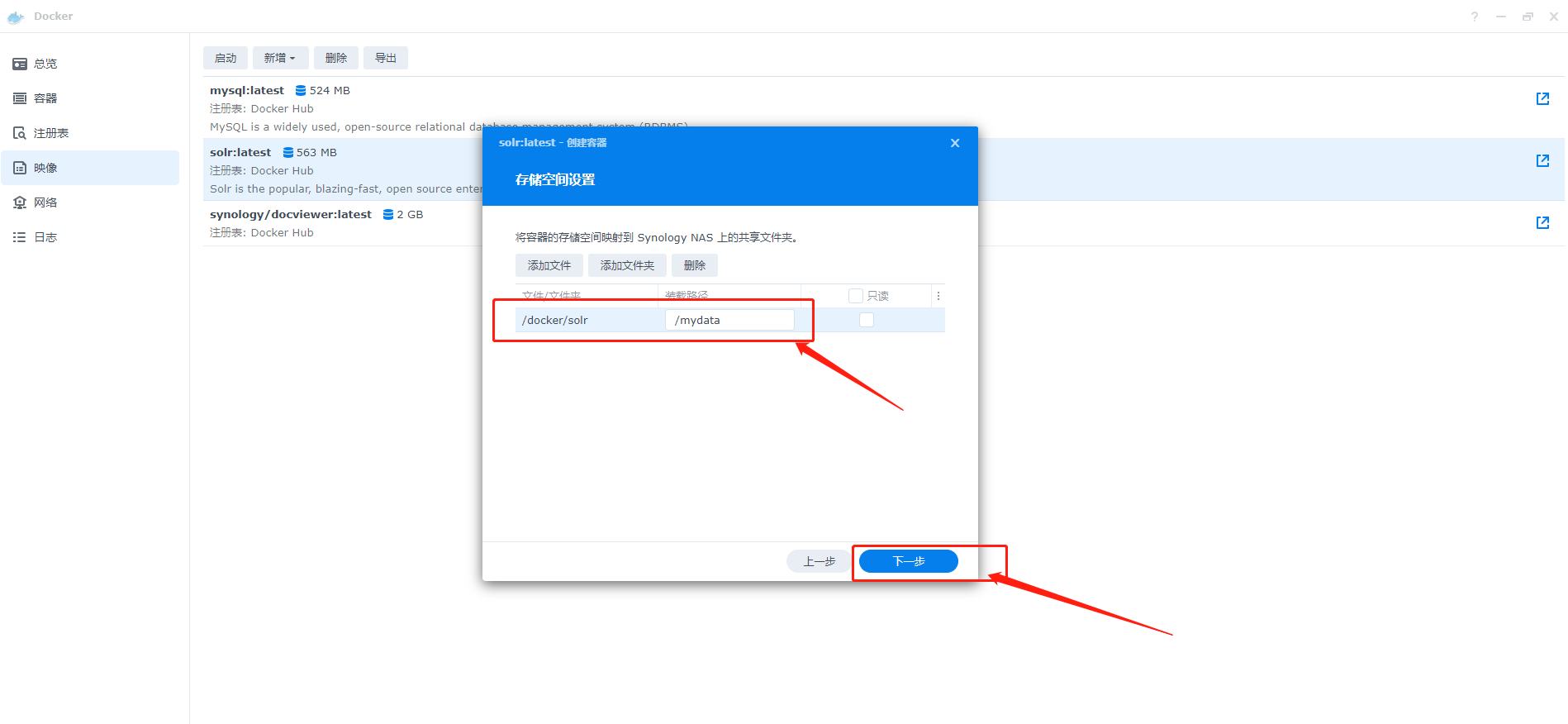
4、Solr的搭建和配置
4.1、创建Core
1、浏览器中访问Nas的端口就可以进入Solr的管理http://192.168.101.92:8983/solr/#/
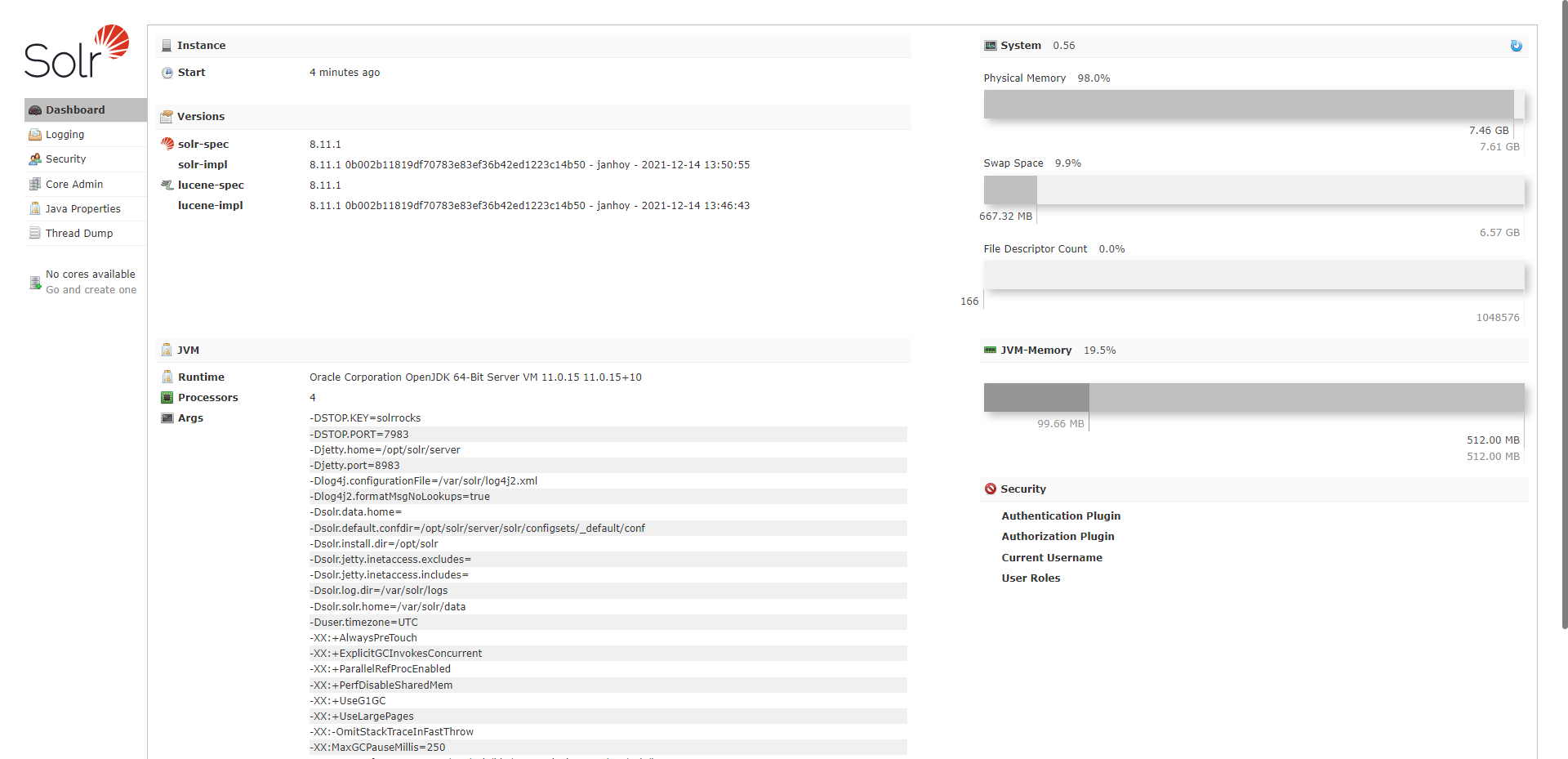
2、首先需要新建一个Core,在Solr中Core就是一个存储的单元,需要注意的是在Core的管理界面并不能直接新建Core,需要复制一份默认的配置文件后才能新建
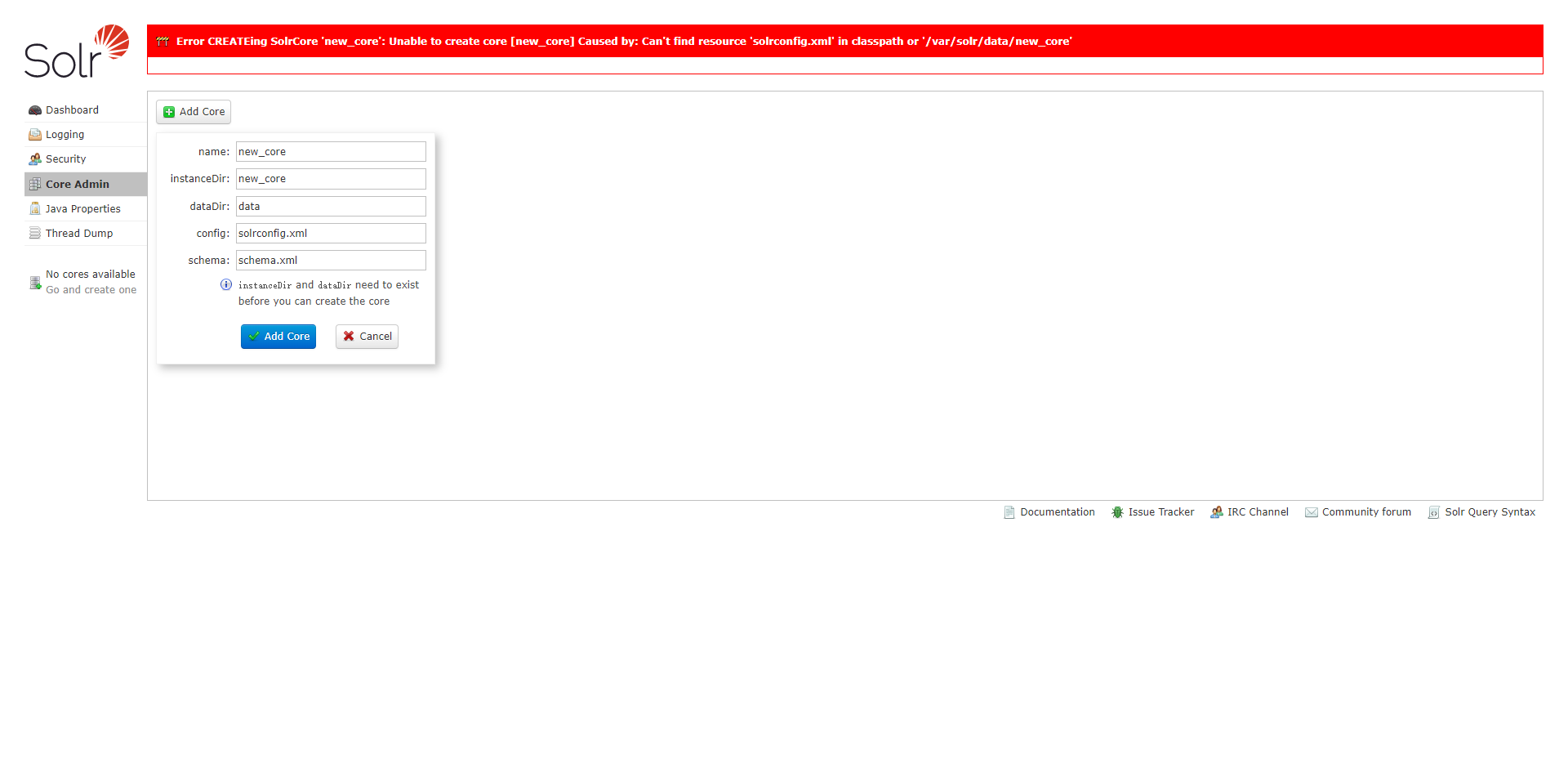
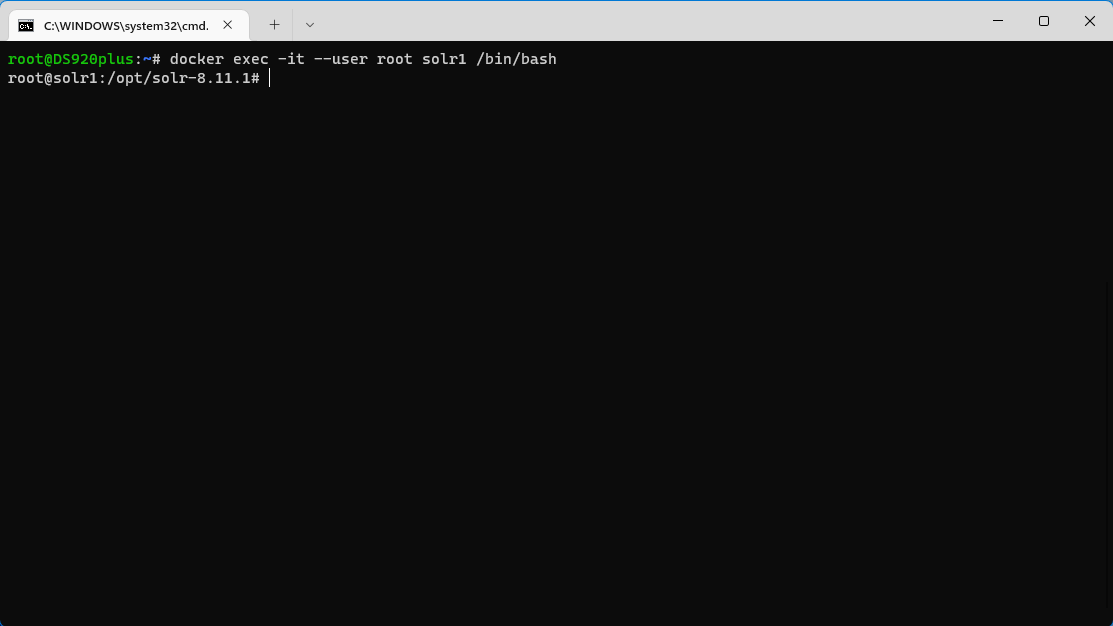
3、由于权限问题,会导致一些Solr文件夹并不能写入文件,所以需要通过SSH连接Nas后在进入Docker进行配置,连接Nas后使用Docker命令进行如容器,root后面跟的是容器的名字
docker exec -it --user root solr /bin/bash
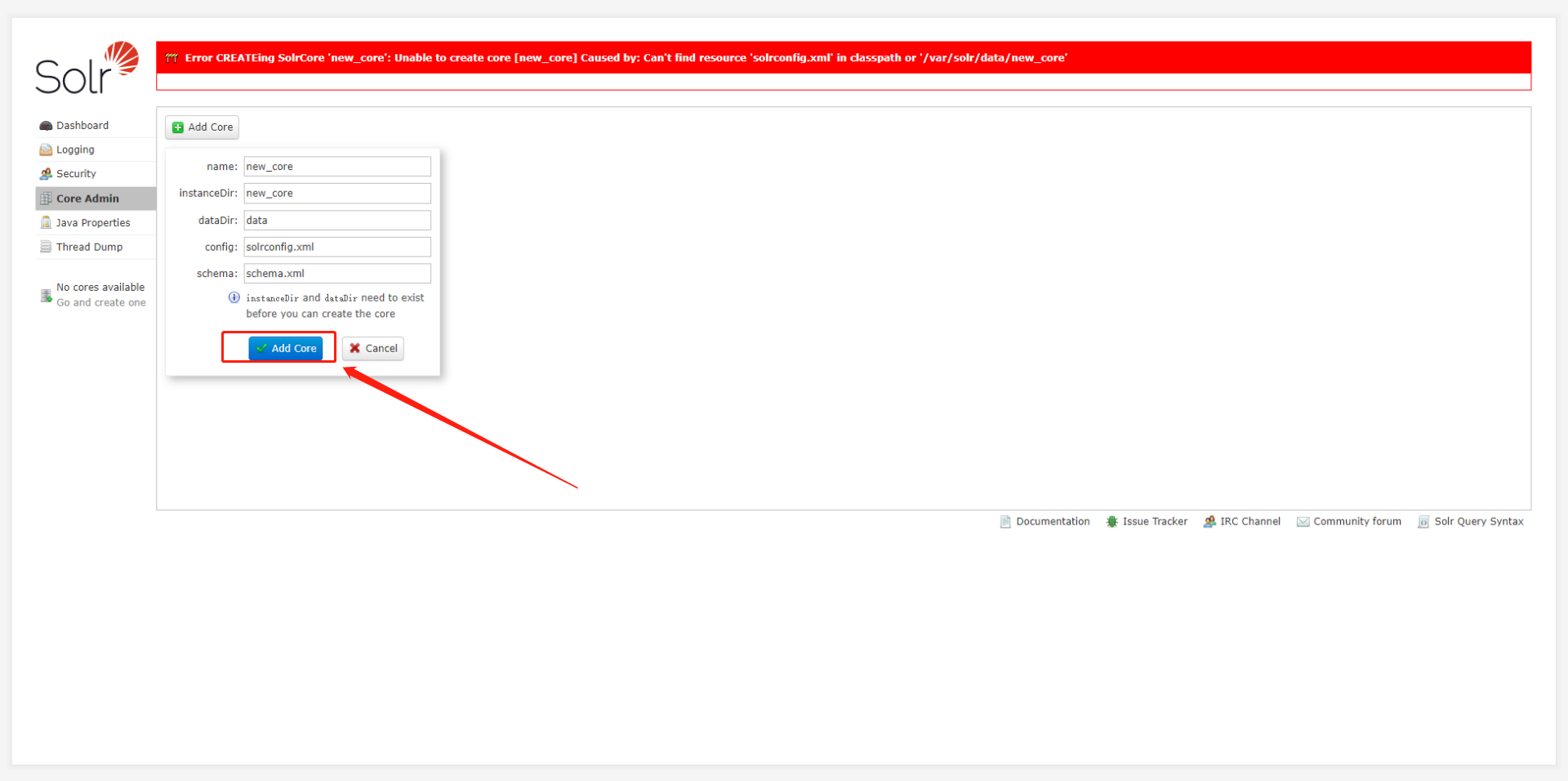
4、使用命令将默认配置文件复制到core中,然后点击添加core就可以成功添加,接下来的配置主要涉及到三个文件, solrconfig.xml, man和data-config.xml
cp -r /opt/solr/server/solr/configsets/_default/conf /var/solr/data/new_core
4.2、导入驱动包
1、将/opt/solr/dist文件夹中的solr-dataimporthandler-8.11.1.jar和solr-dataimporthandler-extras-8.11.1.jar拷贝至/opt/solr/server/solr-webapp/webapp/WEB-INF/lib文件夹中
cp /opt/solr/dist/solr-dataimporthandler-8.11.1.jar /opt/solr/server/solr-webapp/webapp/WEB-INF/lib
cp /opt/solr/dist/solr-dataimporthandler-extras-8.11.1.jar /opt/solr/server/solr-webapp/webapp/WEB-INF/lib
2、下载mysql的驱动包https://repo1.maven.org/maven2/mysql/mysql-connector-java根据mysql的版本下载对应的包,上传至共享文件夹后也拷贝至/opt/solr/server/solr-webapp/webapp/WEB-INF/lib文件夹
cp /mydata/mysql-connector-java-8.0.29.jar /opt/solr/server/solr-webapp/webapp/WEB-INF/lib

4.3、配置文件
1、新建一个data-config.xml文件,上传至容器与Nas共享文件夹中,然后拷贝至/var/solr/data/new_core/conf文件夹内,以下为文件的内容
cp /mydata/data-config.xml /var/solr/data/new_core/conf
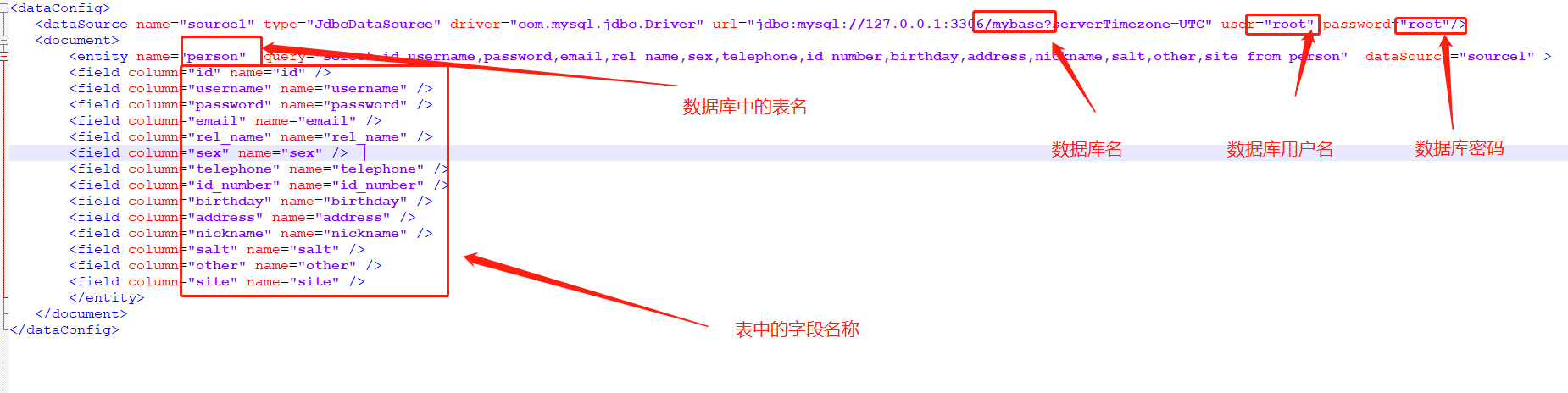
<dataConfig>
<dataSource name="source1" type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/sgk?serverTimezone=UTC" user="root" password="123456"/>
<document>
<entity name="person" query="select id,username,password,email,rel_name,sex,telephone,id_number,birthday,address,nickname,salt,other,site,updata_time from person" dataSource="source1" >
<field column="id" name="id" />
<field column="username" name="username" />
<field column="password" name="password" />
<field column="email" name="email" />
<field column="rel_name" name="rel_name" />
<field column="sex" name="sex" />
<field column="telephone" name="telephone" />
<field column="id_number" name="id_number" />
<field column="birthday" name="birthday" />
<field column="address" name="address" />
<field column="nickname" name="nickname" />
<field column="salt" name="salt" />
<field column="other" name="other" />
<field column="site" name="site" />
</entity>
</document>
</dataConfig>
2、这个文件是负责配置导入数据源的,请按照mysql实际的设置修改datasource的内容,下面entity的内容必须严格按照mysql中社工库表的结构填写,列名要和数据库中的完全一样.
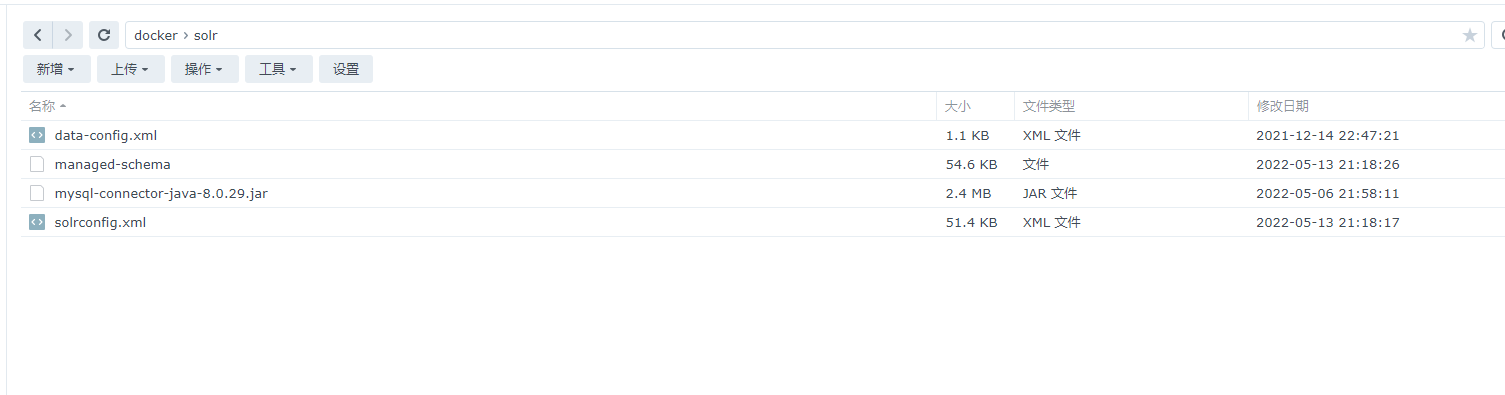
3、执行以下命令将solrconfig.xml和managed-schema 拷贝到容器与Nas共享文件夹中方便修改
cp /var/solr/data/new_core/conf/solrconfig.xml /mydata
cp /var/solr/data/new_core/conf/managed-schema /mydata
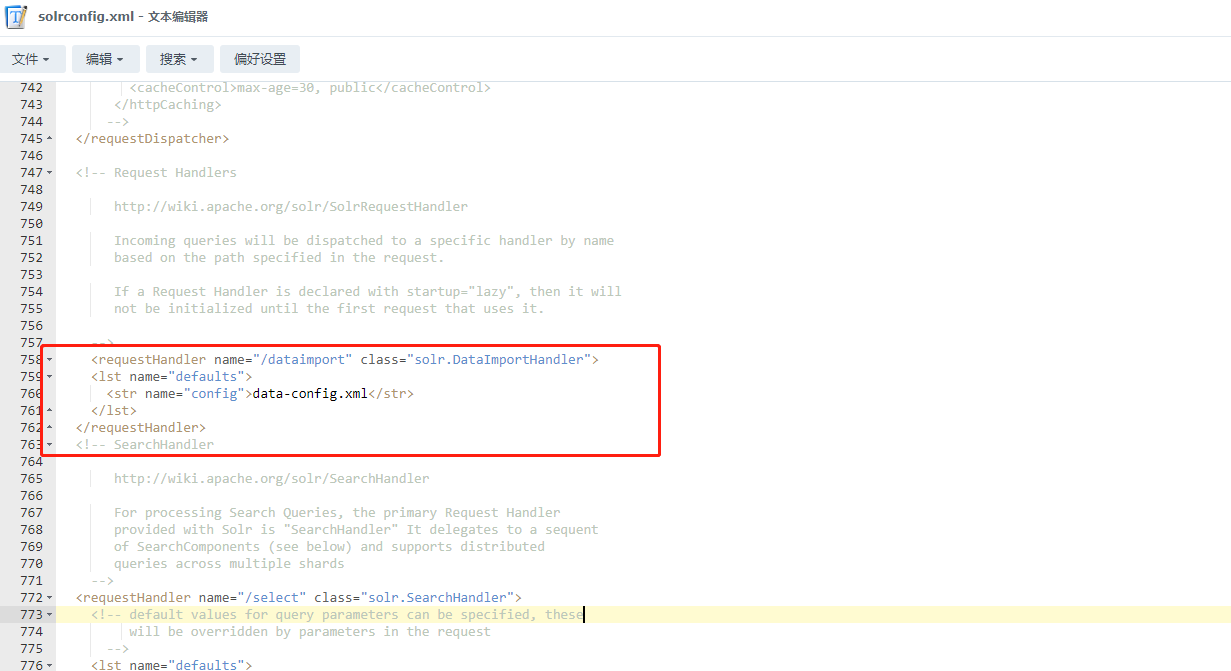
4、使用文本编辑器打开solrconfig.xml文件进行修改,在以下位置插入如下内容
<requestHandler name="/dataimport" class="solr.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
5、将/var/solr/data/new_core/conf中的managed-schema重命名为schema.xml保存一份,然后编辑共享文件夹中managed-schema的
mv managed-schema schema.xml

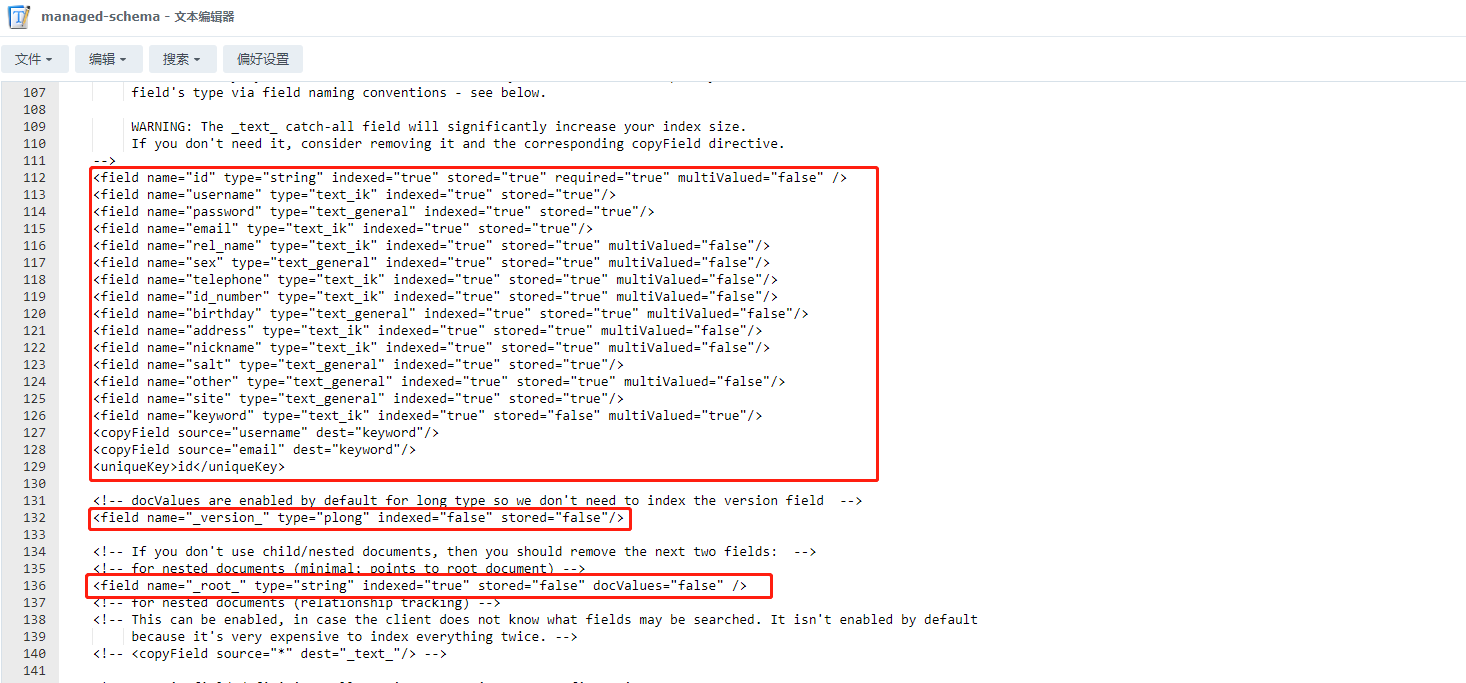
6、只保留version和root节点,然后把所有的field, dynamicField和copyField全部删除,添加以下的部分,text_ik类型为分词器,字段需要作为搜索关键词时,可以使用该类型
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="username" type="text_ik" indexed="true" stored="true"/>
<field name="password" type="text_general" indexed="true" stored="true"/>
<field name="email" type="text_ik" indexed="true" stored="true"/>
<field name="rel_name" type="text_ik" indexed="true" stored="true" multiValued="false"/>
<field name="sex" type="text_general" indexed="true" stored="true" multiValued="false"/>
<field name="telephone" type="text_ik" indexed="true" stored="true" multiValued="false"/>
<field name="id_number" type="text_ik" indexed="true" stored="true" multiValued="false"/>
<field name="birthday" type="text_general" indexed="true" stored="true" multiValued="false"/>
<field name="address" type="text_ik" indexed="true" stored="true" multiValued="false"/>
<field name="nickname" type="text_ik" indexed="true" stored="true" multiValued="false"/>
<field name="salt" type="text_general" indexed="true" stored="true"/>
<field name="other" type="text_general" indexed="true" stored="true" multiValued="false"/>
<field name="site" type="text_general" indexed="true" stored="true"/>
<field name="keyword" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="username" dest="keyword"/>
<copyField source="email" dest="keyword"/>
<uniqueKey>id</uniqueKey>
4.4、IK分词器
1、分词器的作用是分割语句中的词语,分割后的词语方便作为搜索引擎搜索的关键词,solr虽然内置中文分词,但效果并不好,我们需要添加IKAnalyzer中文分词引擎来查询中文,同样下载后上传至共享文件夹,然后复制到/opt/solr/server/solr-webapp/webapp/WEB-INF/lib路径下
https://repo1.maven.org/maven2/com/github/magese/ik-analyzer/8.5.0/ik-analyzer-8.5.0.jar

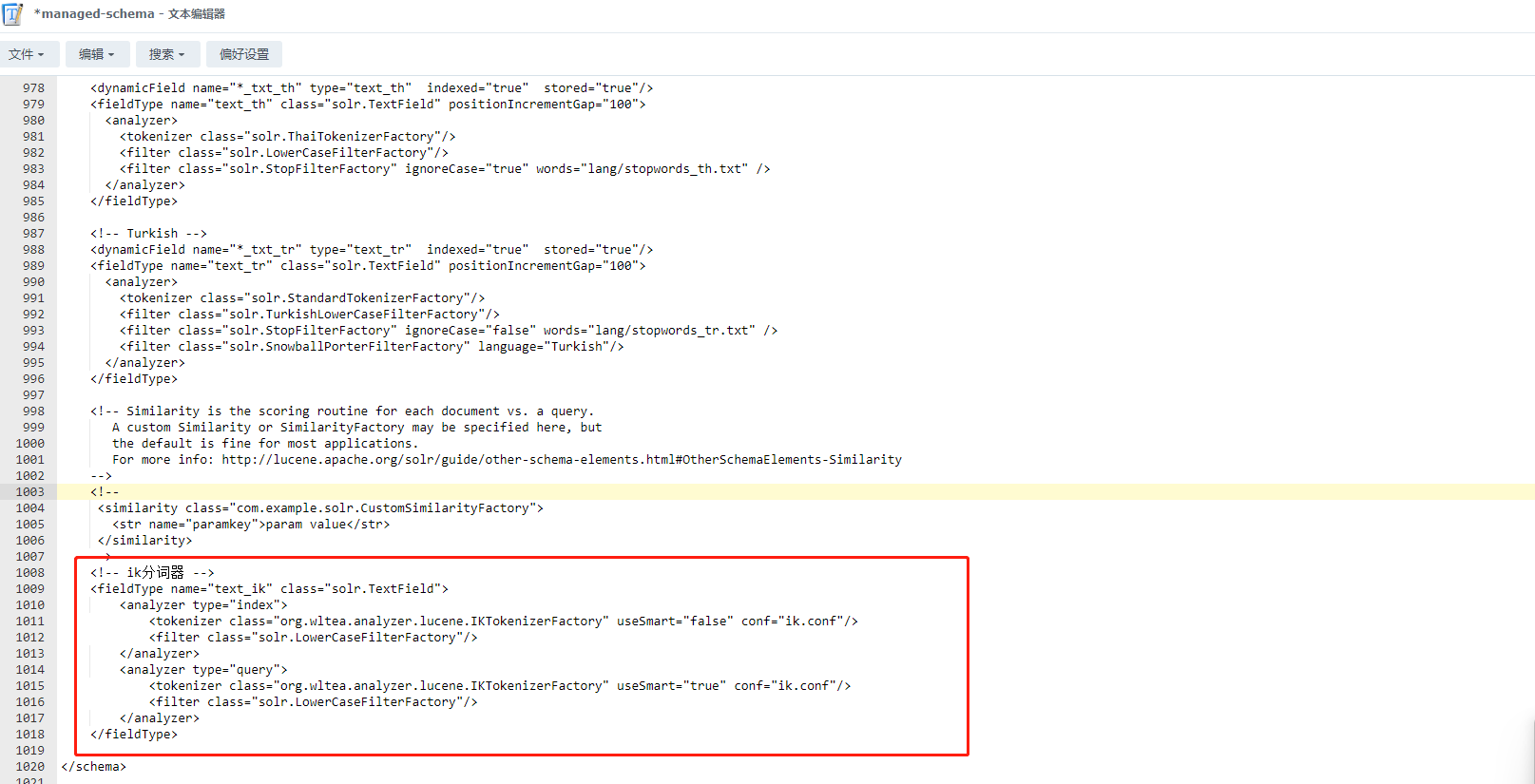
2、在/var/solr/data/new_core/conf下的managed-schema文件中添加以下内容,也可通过在Nas的共享文件家中修改后复制到该路径
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
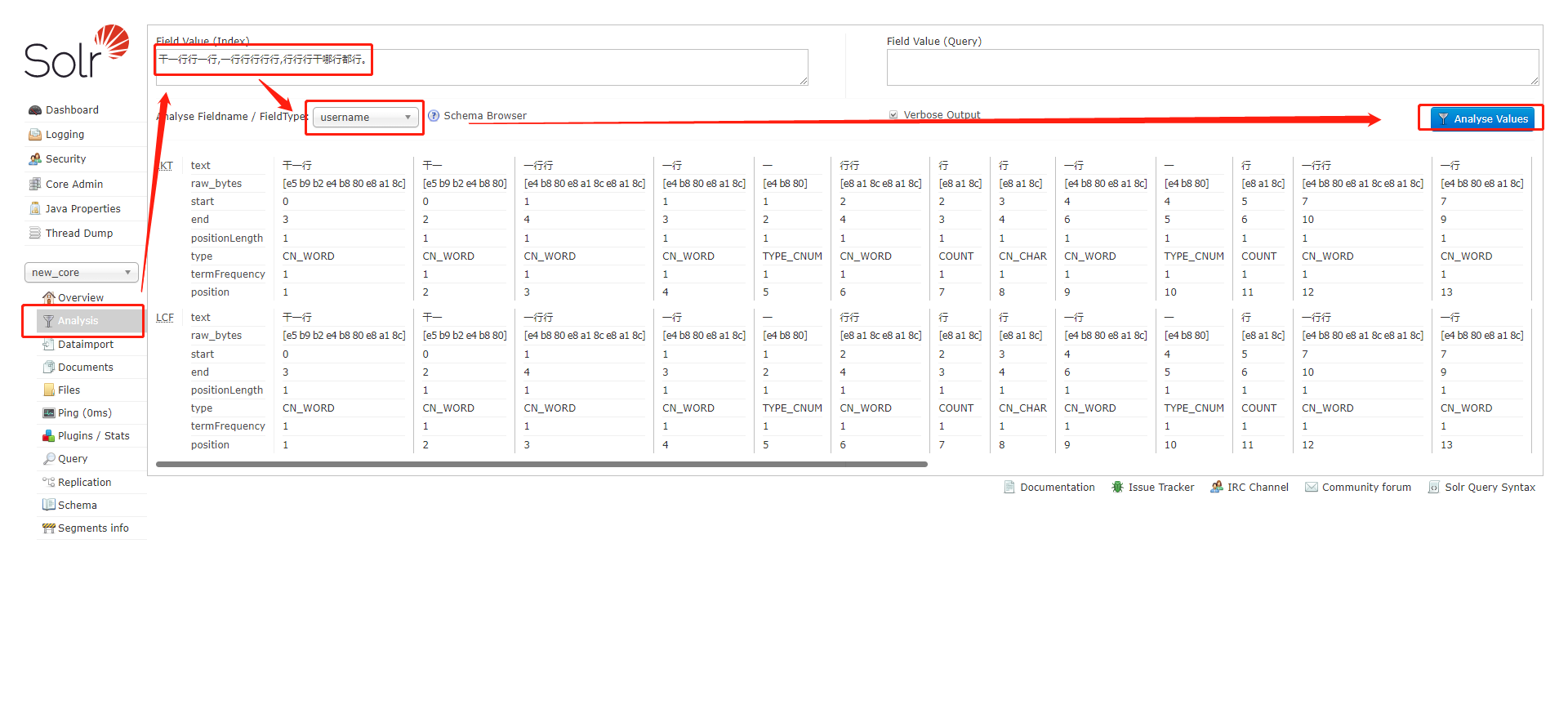
3、以下是分词器的使用测试
4.5、数据导入
1、首先需将测试数据通过Navcit导入mysql数据库
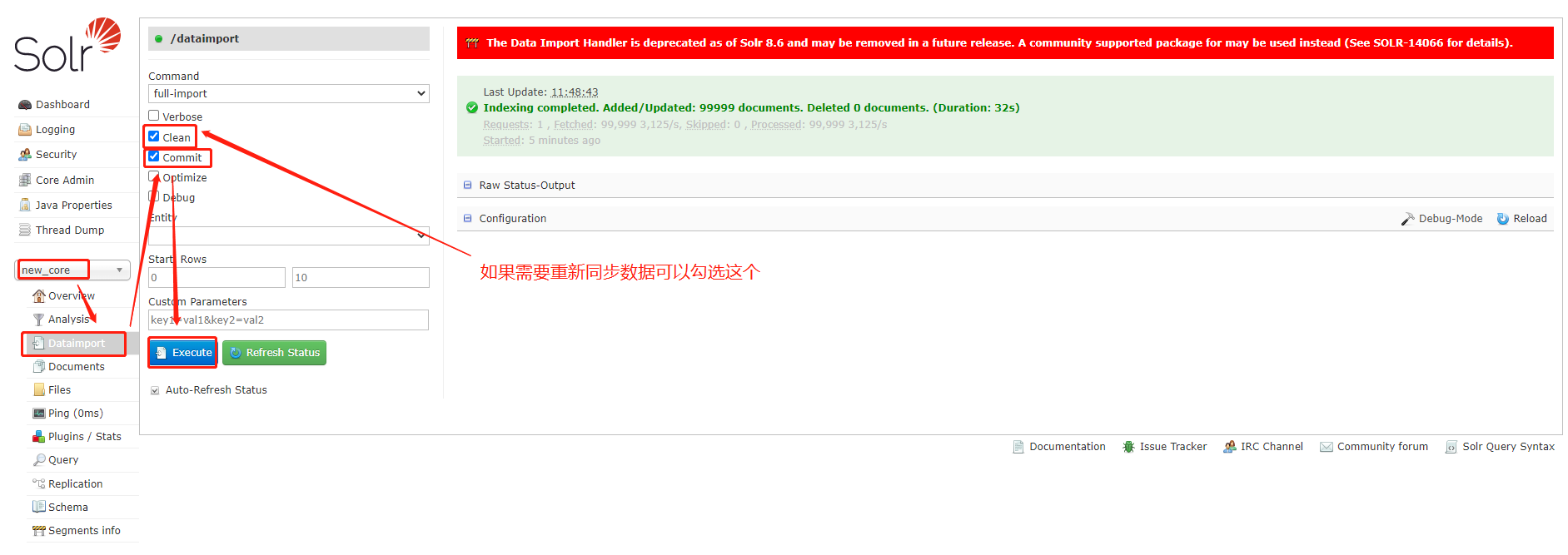
2、在数据导入功能处进行数据同步,同步完成后就会显示绿色的提示
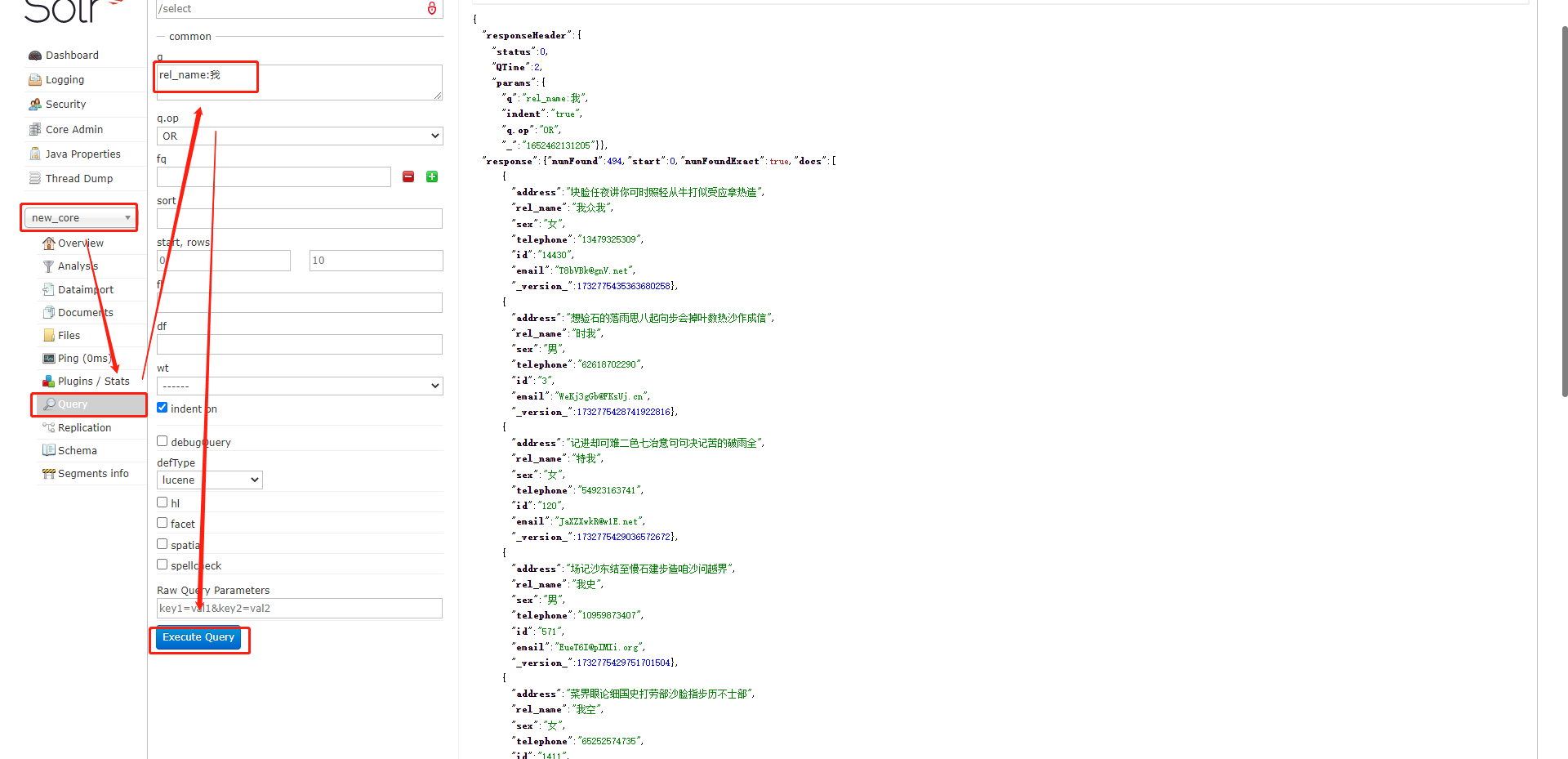
4.6、数据查询
3、数据查询测试,可以发现能够进行成功查询
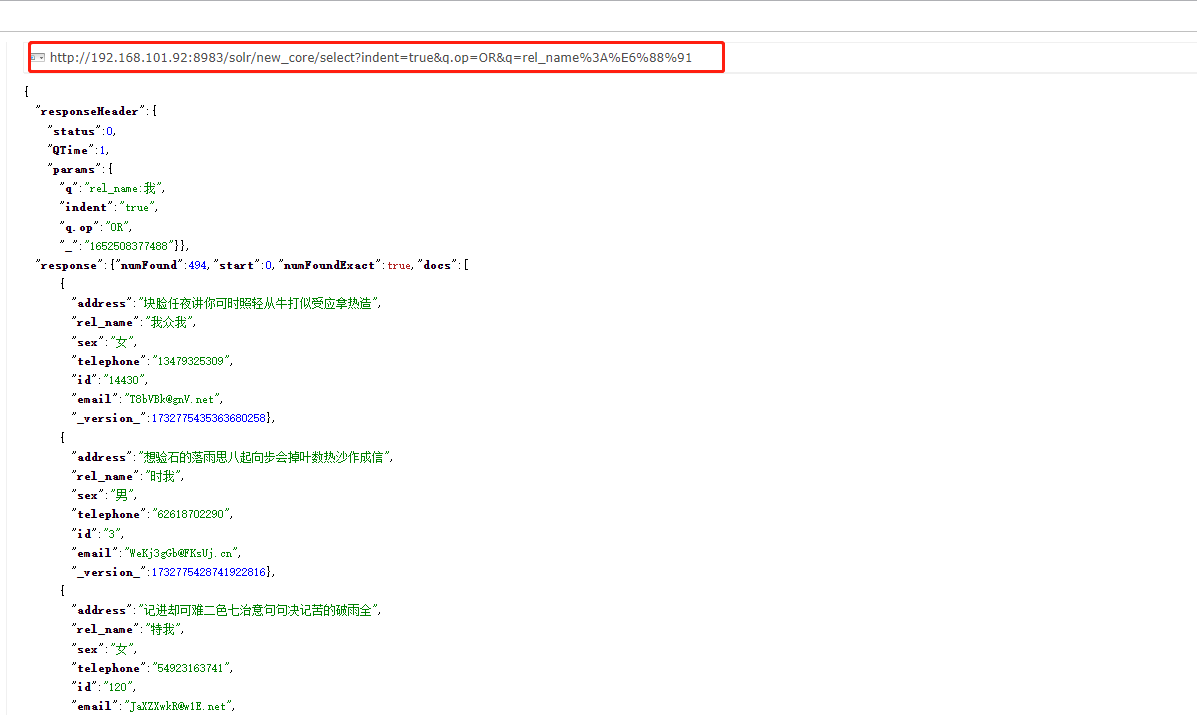
4、后续的数据查询只需要构建url链接进行数据请求,就可以查询到数据了
注意事项:所有Docker中的时间需与服务器时间同步,否则在后续的设置增量导入时导致无法导入成功
评论区